Hey Guys,
We are reading lot about AI/Deep learning to do some really smart stuff such as playing G0 game, recognizing images and speech. The core part of the Deep learning is the deep neural network (DNN). Before we understand DNN, we need look at the shallow neural network and its property called the universal approximation, which means that given input variable 


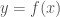
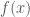

Problem in hand:
Before predicting if the image has cat or not, we need to build the model by showing many cat and not cat images to the model. We have a set of samples (cat/non-cat images) of the input 
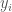
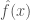

- Expressiveness of the model: The underlying function
. For example we can simply say the
, which represents the line with the
. But the line can represent only some functions from
, we will not be able to approximate some functions
) . For example, see the figure below. It shows the coffee consumption in cups vs time of the day, you see that the function that is required to predict the cups of coffe given the day is not a line and non-linear function is required to approximate that underlying function. In many cases, the input data dimension will be more than two and we will not be able to visualize data and decide the function. So we need a function that has the capability to express broad class of function. But having flexible function also can have problem of over-fitting in case of less data settings, we will not be discussing in this post. We assume that we have lot of data.

- Learning method: Learning methods deals with learning the parameters
We assume that we have the best learning method and try to understand the expressiveness alone. There are several papers that handles from the mathematical perspective that i included in the reference. But here, we take graphical perspective to intuitively understand the expressiveness of the neural network using some simple function to very complex functions in one dimension input and one dimension output.
Before we understand the expressiveness of the neural network, let us quickly review the neural network (single layer) and also called as shallow networks.
What are Neural Networks:
The shallow networks are the function which takes the input

where,




How Neural Network can approximate any function:
To understand the neural networks approximation property, Let us fix the activation function to sigmoid

If we consider x as one dimension, the value of the function for different values of a,b is shown below.

left: b=0 and right: b=-.5. Different color shows the different values of a.
You can observe from the figure that the value of changes the slope of the function for small interval around the bias b. You can play with the function here to understand more.
Now let us consider a function 

FUNCTION-1: Line x+.5 in the interval [0,1].
The under lying function and function approximation learned by the NN with single neuron is shown below. As you can see that the neural network is able to approximate well with the line using single neuron in the observed data interval [0,1].

x-axis indicate the input x and y-axis indicates the output y. blue line indicate the underlying function [latex]f=x+.5[/latex], green points indicate the observed data points [latex](x_i,y_i)[/latex] and green curve indicates the approximate function learned by the NN with single neuron.
FUNCTION-2 : LINE X+.5 IN THE INTERVAL [-0.5,1.5]
Let us consider the same function and increase the interval of the observed data to [-.5 – 1.5]. Learn the neural network from the data and you see that the single neuron is able to approximate this function where the data is observed. (of course different learnt parameters).
Ok, Let us little formal how that is possible with single neuron. The function of single neuron is given by 


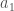
FUnction-3: Two lines
Let us consider little more complicated function where two different line for different interval of x-axis. The function is 

FUNCTION-4: THERE LINES
In this example we try to approximate 3 lines using 3 neurons. I am showing the each sigmoid functions learned by the neural network below the three line curve. As you can clearly see that the each of the sigmoid is trying to approximate the one part of the line.

FUNCTION-5: SINE wave
Let us look at little more complex function such as sinosoidal function 

The above graph shows the approximate function learned by the neural network for different number of neurons. As you can see the one trying to fit the center part of the sine way where the long interval of linear region the added neurons are trying to fit to the other part of the sine wave.
MANY MORE functions

parabola with linear trend

2nd degree polynomial

3rd degree polynomial

Complex function
In all the above functions, you can see that the NN is trying to approximate the some interval of the function using sigmoids.
No matter what function is there the input can be divided into small chunks where the function is continues and approximate the part by a sigmoid function. This why the neural networks are called universal approximators.
So adding more neurons will increase the expressive power of the NN. You can think of NN as a picewise interpolation method using the kernel as its activation function.
Now you can generalize this concept to any activation. The NN will try to approximate the small chunk of the function using its activation. Same concept can be understood in this nice blog using threshold activation instead of smooth activation.
If neural networks are universal approximators , why do we need to explore any other models?
What are the problems:
Let us consider a function 

Approximately we need 60 neurons to approximate this simple function. So the universal approximation does not specify the number of neurons required to approximate some with function with some error. In practice this number will be really high for marginally complex function. The neural network is failing to exploit the nice compositional structure present in the function.
In my next post we see how the DNN can overcome this problem.
Thanks,
Achuth
References:
[1] Hornik, Kurt, Maxwell Stinchcombe, and Halbert White. “Multilayer feedforward networks are universal approximators.” Neural networks 2.5 (1989): 359-366. (Main and first paper)
[2]Scarselli, Franco, and Ah Chung Tsoi. “Universal approximation using feedforward neural networks: A survey of some existing methods, and some new results.” Neural networks 11.1 (1998): 15-37.
[3] Cybenko, George. “Approximation by superpositions of a sigmoidal function.” Mathematics of Control, Signals, and Systems (MCSS) 2.4 (1989): 303-314.

Great Article!
“No matter what function is there the input can be divided into small chunks where the function is continues and approximate the part by a sigmoid function. This why the neural networks are called universal approximators.”
This summed up the article really well!
Found one error:
In the figure description under the heading: “FUNCTION-1: LINE X+.5 IN THE INTERVAL [0,1].”
you meant “x-axis indicate the input x………and red curve indicates the approximate function….” but you wrote “green curve” instead of “red curve”!
LikeLike