Introduction:
As per the source-filter model,we can see our speech production system as excitation at the glottis passing through a acoustic filter(vocal tract). As you see the below figure the excitation is approximately a impulse train(voiced speech) and the filter has smooth frequency response depending on the what phoneme is been spoken(vocal tract shape). In time domain the impulse train is convoluted with the filter impulse response to get the speech(similarly multiplication in time domain).

Figure 1: Source-Filter Demo on 25 ms speech: Left-Top:source impulse train,Right-Top: frequency response of impulse train with hamming window,Middle: impulse and frequency response of the filter.
The main goal of the Spectral Estimation technique is to recover the frequency response of the filter(Middle-left:
The parameterization of the filter is useful in compressing the frequency response of the filter. This will be help reducing the bandwidth required in communication or modelling speech with less number of parameters for various purpose like speech recognition,text to speech etc.
In this article we explore briefly about some of the famous spectral estimation technique used speech processing, disadvantages of them and how the Mel-Generalized Cepstral estimation over comes that disadvantages. This article is mainly focused on understanding intuitively/graphically with less math. The mathematical details can found the respective PDF links given.
Review of some of the methods:
Please refer the references for more details,here i just give intuitive explanation of each method.
- Linear Predictive Coefficients(LPC): In this method the
. This will start failing if the system is not all-pole,for instance like nasals that has zeros. The LPC will not be able to recover the filter response in the place of zeros. As shown in the Figure 2. Refer these links to understanding the estimation of the coefficients(a)[1][2][3].
- Cepstrum: Since the LPC cannot recover the
is represented by the all-pole model(
- Mel-Scale: So-far we saw only representing the
- Mel-LPC:
- Mel-Cepstrum:(
)
- where
and
controls the trade off the resolution in high and low frequency.
- where
- Mel-LPC:
[*]Accurately representing the speech spectrum is not our goal..! we have to represent the vocal tract response more accurately. Think about what happens as the M increases in case of LPC and cepstrum?
The diagrams shows a synthetic spectrum generated from poles at angle of 0,45,75 degrees. The radius of the pole/zero is mentioned in the plot. As per the diagram, the spectrum with zeros closer to unit circle(0.9) are better approximated by the cepstrum than the LPC. Similar the spectrum with poles are better approximated by LPC than cepstrum. If the spectrum has both zeros and poles, both methods are not able to approximate the spectrum. So Spectral estimation of speech by mel-generalized cepstral analysis and MEL-GENERALIZED CEPSTRAL ANALYSIS — A UNIFIED APPROACH TO SPEECH SPECTRAL ESTIMATION proposes a unified frame work where it can combine these methods.
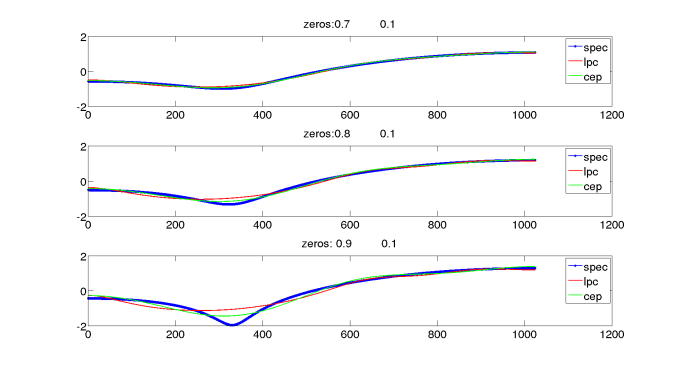
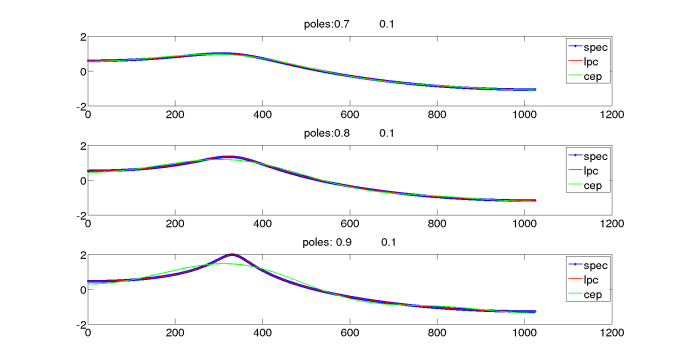
Figure 2: The comparison of the original spectrum and the approximated spectrum by LPC and cepstrum method for various pole or zero locations.
Spectral estimation of speech by Mel-generalized cepstral analysis:
The filter response 




There are 5 main ideas of the papers as mentioned below:
1. Generalized logarithm:
As we saw earlier the LPC and cepstrum comparison where the compression of spectrum decides the approximation of the spectrum envelope. So we need a operator that decides the compression factor(denoted by 

The

The synthetic spectrum after generalized logarithm transform for all-pole(top) and all-zero(bottom) systems.
As per the diagram the the different
2. Unbiased estimation of log spectrum:
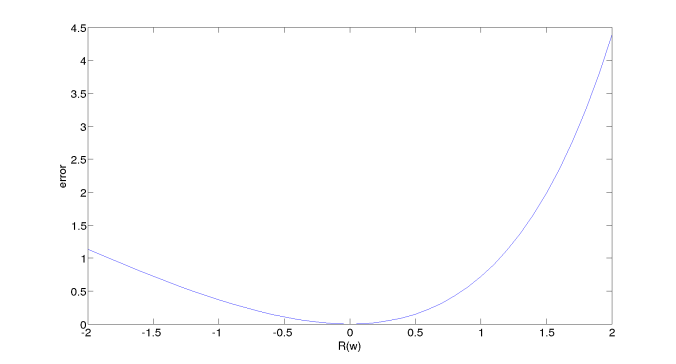
The error function minimized to estimate the coefficients is given by

and 

The error function is very crucial to estimate the envelope because this error function penalizes the +ve error less than the -ve error. The error function for 
This very helpful in the speech is because the envelope information in the spectrum is sampled by the pitch. So that the direct mean square error(penalized equally the +ve and -ve errors) is not preferred compared to the error mentioned above. The mean square allows both +ve error and -ve errors, but the actual envelope will not have any -ve errors.
3. Warping:
The 


4. Gain independent form:
The LPC(

Where 
Given the above 4 ideas the representation(a or b) can be found by optimizing the error(E) with respect to a or b. If we consider optimizing with respect to b. substituting the basis change to the E and simplifying gives the simplified error function as shown below. The proof can be found here. 
5. Direct synthesis filter from the coefficients:
As mentioned earlier the 


The optimization is performed using the gradient descent/newton method that needs first and second order derivatives. Its computation can be found here.
The other advantages of the method:
- The error function is convex with respect to the coefficients b.(proof can be found here)
- The coefficients of the synthesis filter is always stable(proof can be found here)
Simulations using different synthetic spectrum:
role of :
As we discussed before the
As shown in the diagram, In all spectrum shape the
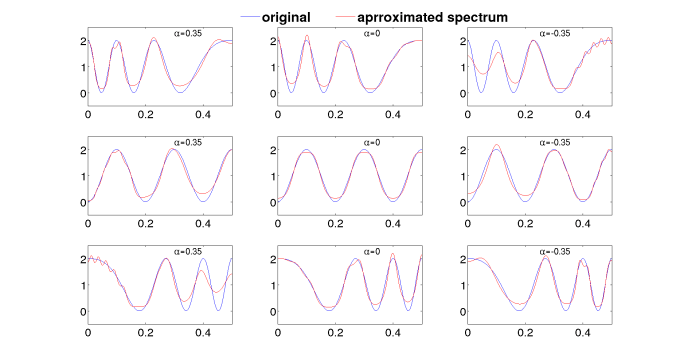
Spectrum approximation by 16th order MGC with different value of alpha and gamma=0 for different kind of variations at lower and higher frequency regions.
Do we really have fine control on all frequency resolution using a single parameter
role of :
As discussed before, the
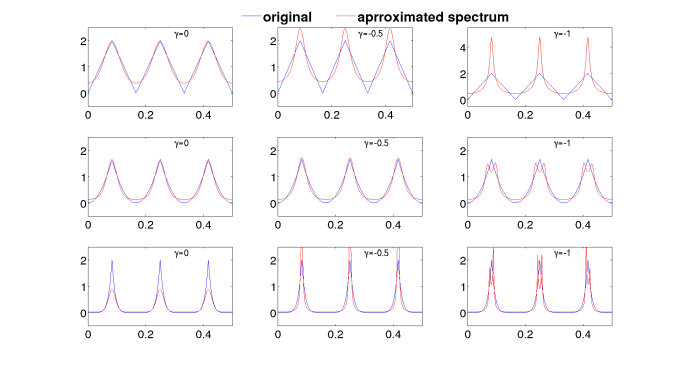
Spectrum approximation by 16th order MGC with different value of gamma and alpha=0
Similarly both
Discussion:
Even though we have the flexibility of controlling the spectrum approximation using MGCs. It has the following shortcomings.
- The frequency resolution at given band cannot be increased compared to the out off band. This limitation is because of form of frequency warping is used in the method.The flexibility of this can be increased to have better control on frequency resolution.
- The generalized log will compress all the bins of the spectrum depending on
- The value of
